
股票收益预测:如何设计跨行业预测的机器学习模型?
量化投资与机器学习微信公众号,是业内垂直于 量化投资、对冲基金、金融科技、人工智能、大数据等领域的主流自媒体。公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业40W+关注者,曾荣获AMMA优秀品牌力、优秀洞察力大奖,连续4年被腾讯云+社区评选为“年度最佳作者”。
作者:Matthias Hanauer、Amar Soebhag、Marc Stam、Tobias Hoogteijling
本文研究了在股票收益预测中,是否需要使用行业特定的机器学习模型。作者比较了三类模型:一体化的“通才”(Generalist)模型、行业特定的“专家”(Specialist)模型,以及结合两者优势的“混合”(Hybrid)模型。研究发现,混合模型在样本外预测能力上明显优于专家模型,且在多个衡量标准上略优于通才模型,特别是在夏普比率和风险控制方面表现突出。通过美国与国际股票市场的实证分析,文章证明——将行业意识嵌入统一模型中,可以有效提高预测精度与投资组合的风险调整收益。核心观点包括:
不同行业之间存在显著的预测异质性;
单一通才模型容易造成行业倾斜,导致风险加大;
混合模型在兼顾行业结构和样本量的同时,提升了学习效率和估计精度。
不同行业之间存在显著的预测异质性;
单一通才模型容易造成行业倾斜,导致风险加大;
混合模型在兼顾行业结构和样本量的同时,提升了学习效率和估计精度。
是否需要对行业单独训练特定的模型?
近年来,机器学习在资产定价中的应用迅速增长,大多数研究构建的模型都基于“一个横截面预测一切”的前提,即通才模型。然而,既有文献表明行业结构影响定价机制——企业间因所处行业不同而面对不同的市场摩擦、宏观冲击和监管环境。传统机器学习模型大多采用“一刀切”的通才策略,将所有股票纳入统一框架进行收益预测。这种做法忽视了行业间潜在的异质性:
行业内企业面临相似宏观冲击、监管环境与供需结构;
投资者与分析师在行业层面具备更强信息处理优势;
实证研究显示风险溢价存在行业差异。
行业内企业面临相似宏观冲击、监管环境与供需结构;
投资者与分析师在行业层面具备更强信息处理优势;
实证研究显示风险溢价存在行业差异。
因此,有必要探讨不同模型设计对预测准确性和风险管理的影响。
模型设计
展开全文
作者基于153个来自Jensen et al. (2023)的特征变量,构建并比较以下三种模型:
Generalist模型:通用训练,忽视行业特征;
Specialist模型:每个行业独立建模;
Hybrid模型:使用所有股票样本,但特征与目标值在行业层面标准化,实现隐性行业建模。
模型分别采用四种算法:Elastic Net(线性)、GBRT(树模型)、NN3(三层神经网络)、ENS(集成平均)。
数据来源与处理:涵盖1957–2023年美股市场,排除微盘股;使用Fama-French行业分类;
滚动训练与测试:使用18年训练集+12年验证集+1年测试集的滚动窗口设计;
目标变量:分别为全市场中位数、行业中位数的超额收益;
评价指标:
OOS R²(平均交叉样本R²)
信息系数(IC,预测与真实排名的Spearman相关系数)
投资组合的经济指标:夏普比率、最大回撤、组合分权测试(spanning tests)
Generalist模型:通用训练,忽视行业特征;
Specialist模型:每个行业独立建模;
Hybrid模型:使用所有股票样本,但特征与目标值在行业层面标准化,实现隐性行业建模。
模型分别采用四种算法:Elastic Net(线性)、GBRT(树模型)、NN3(三层神经网络)、ENS(集成平均)。
数据来源与处理:涵盖1957–2023年美股市场,排除微盘股;使用Fama-French行业分类;
滚动训练与测试:使用18年训练集+12年验证集+1年测试集的滚动窗口设计;
目标变量:分别为全市场中位数、行业中位数的超额收益;
评价指标:
OOS R²(平均交叉样本R²)
信息系数(IC,预测与真实排名的Spearman相关系数)
投资组合的经济指标:夏普比率、最大回撤、组合分权测试(spanning tests)
OOS R²(平均交叉样本R²)
信息系数(IC,预测与真实排名的Spearman相关系数)
投资组合的经济指标:夏普比率、最大回撤、组合分权测试(spanning tests)
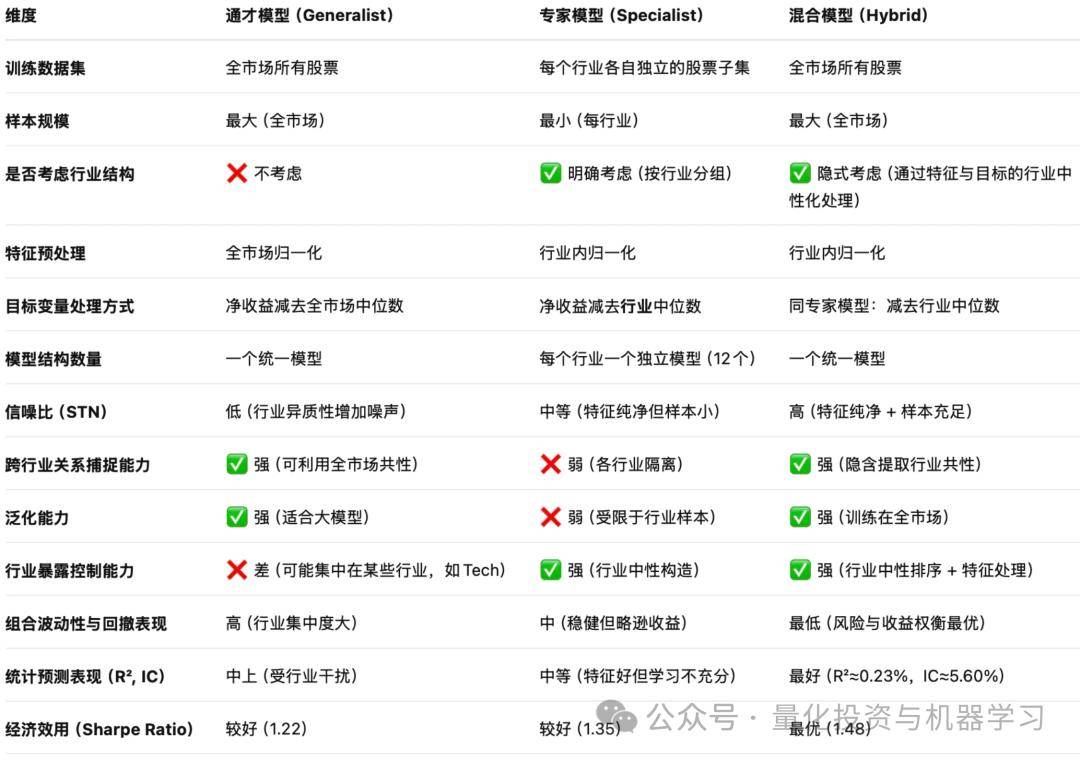
以下是论文中三种模型(通才 Generalist、专家 Specialist、混合 Hybrid)在关键维度上的异同的对比表:
实证结果
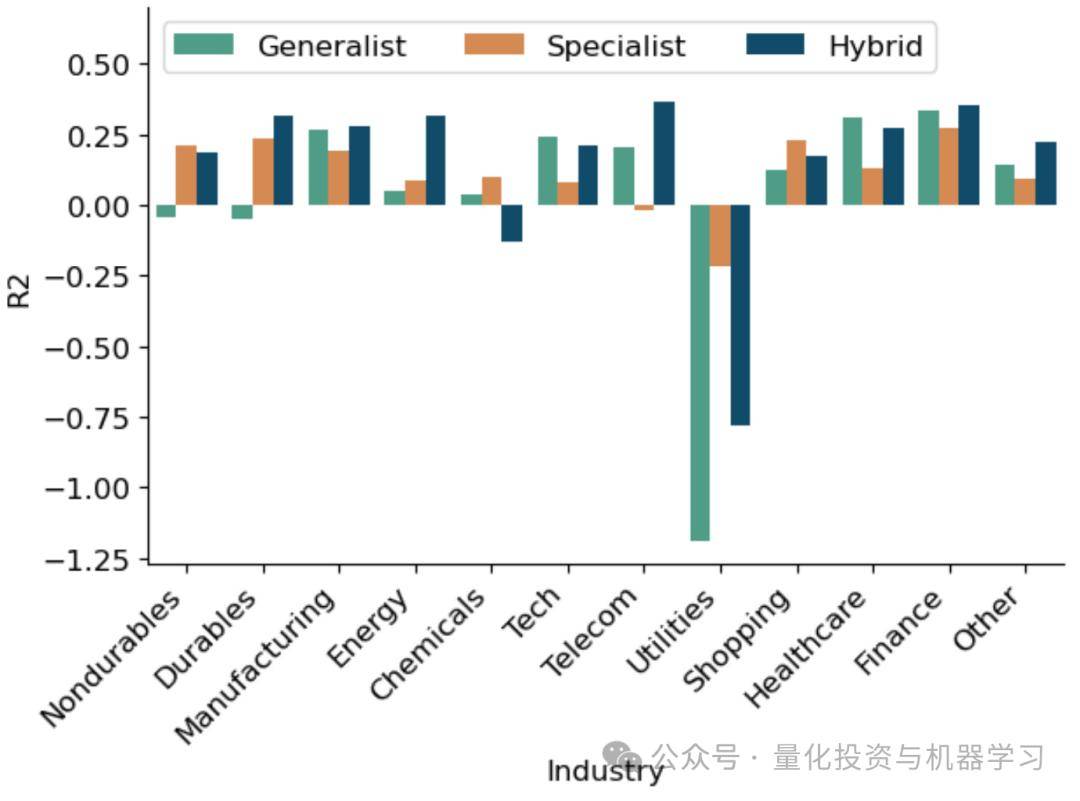
Generalist 模型存在显著行业倾斜(尤其是科技 Tech 行业),显示出其“无意识”地集中过度投资于某些行业。相比之下,Hybrid 和 Specialist 模型通过行业中性化排序或独立建模,显著降低了行业暴露偏移风险。
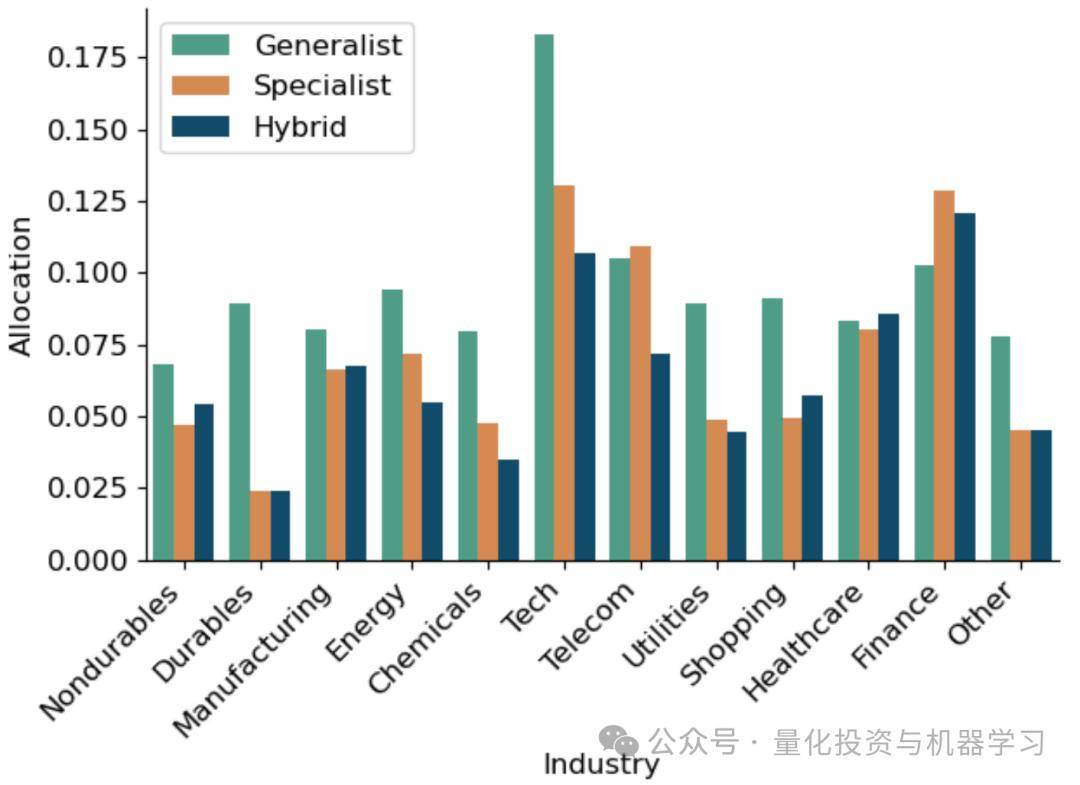
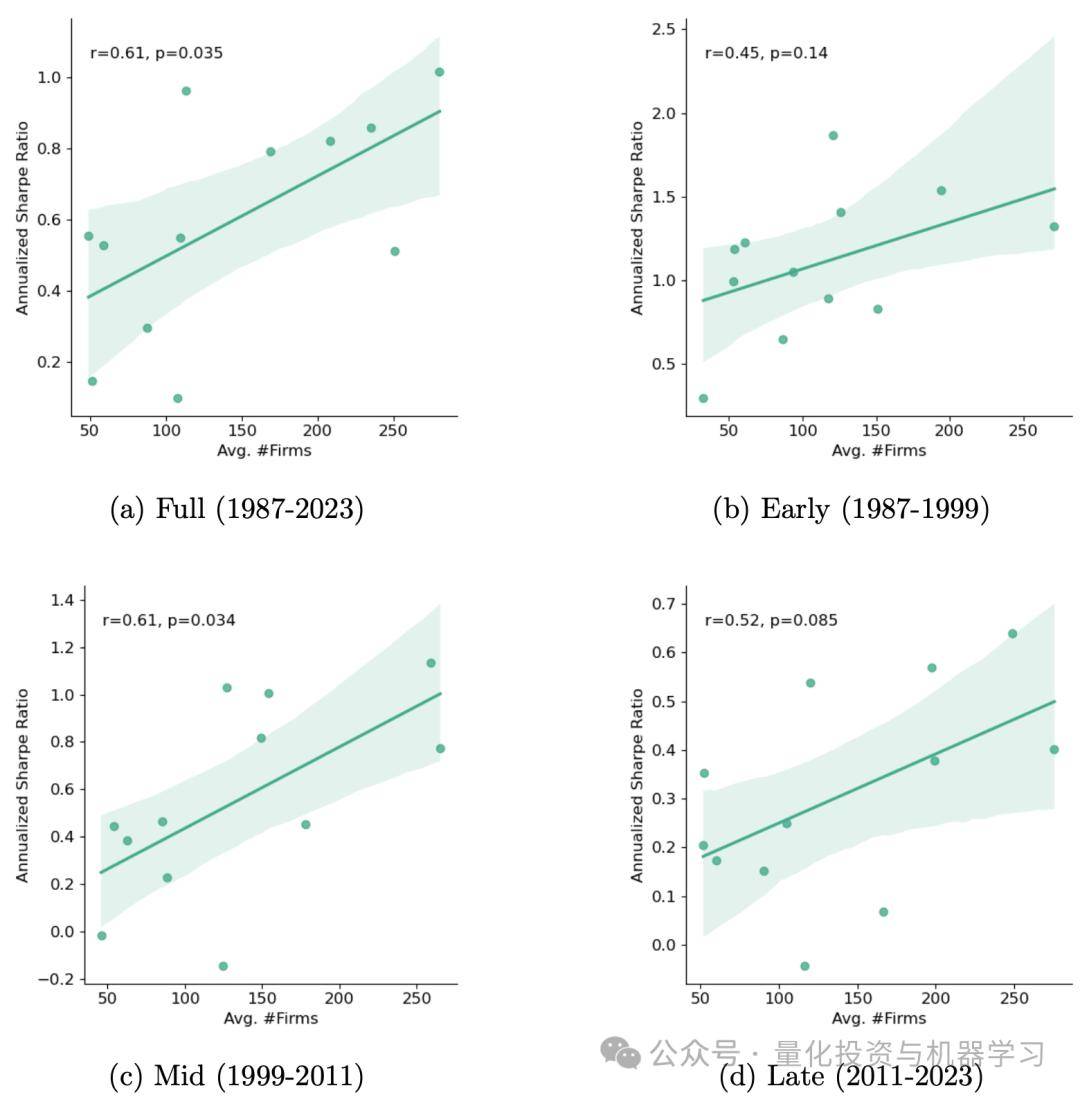
专家模型的预测效果(Sharpe)与行业样本数量正相关。样本多的行业,如金融(Finance)和科技(Tech),专家模型效果更好;而样本少的行业预测效果显著下降。这解释了为什么 Specialist 模型总体上表现不如 Hybrid 模型。
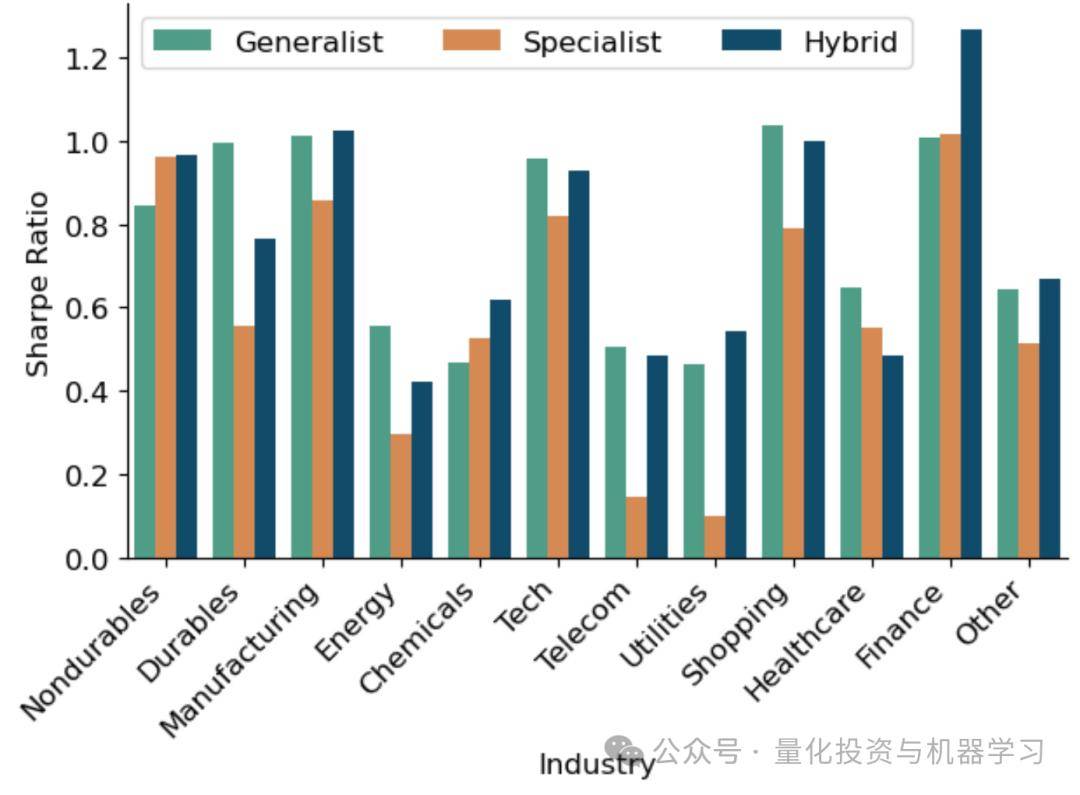
Hybrid 模型在半数行业中表现最好,其次是 Generalist,而 Specialist 表现最弱。这表明即使在行业内部预测收益时,混合模型也比完全行业分组训练更稳健,具备较强的一致性。
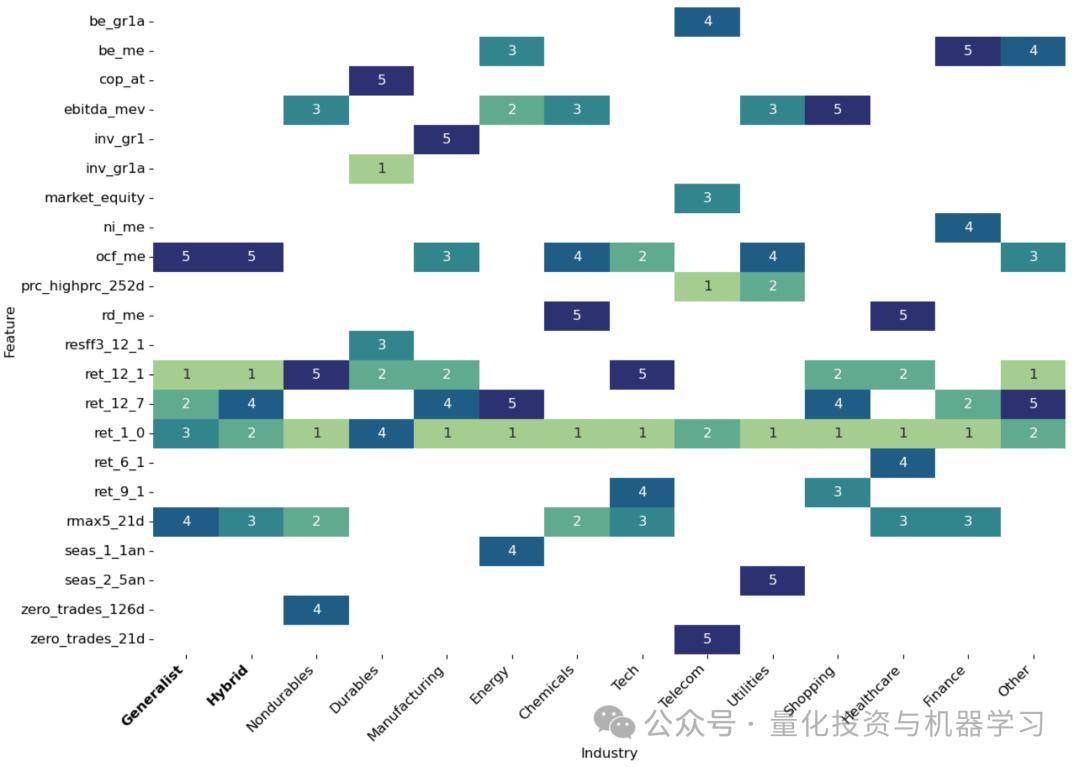
该图展示了特征的重要性在行业间的稳定性与差异性。例如,“短期反转”(ret_1_0)、“动量”(ret_12_1)、“skewness”等变量是多个行业共享的重要预测因子,而某些特征只在特定行业有效。说明收益预测中既存在共通因子,也存在行业特有因子。
Hybrid 模型构建的投资组合在整个样本期(1987–2023)中表现出最稳定、持续增长的收益曲线。通过对每月收益进行波动率调整,图中清晰显示出 Hybrid 策略在控制风险基础上实现了更高的收益积累。这说明该模型在实证中不仅预测能力强,而且具备显著的经济效用。
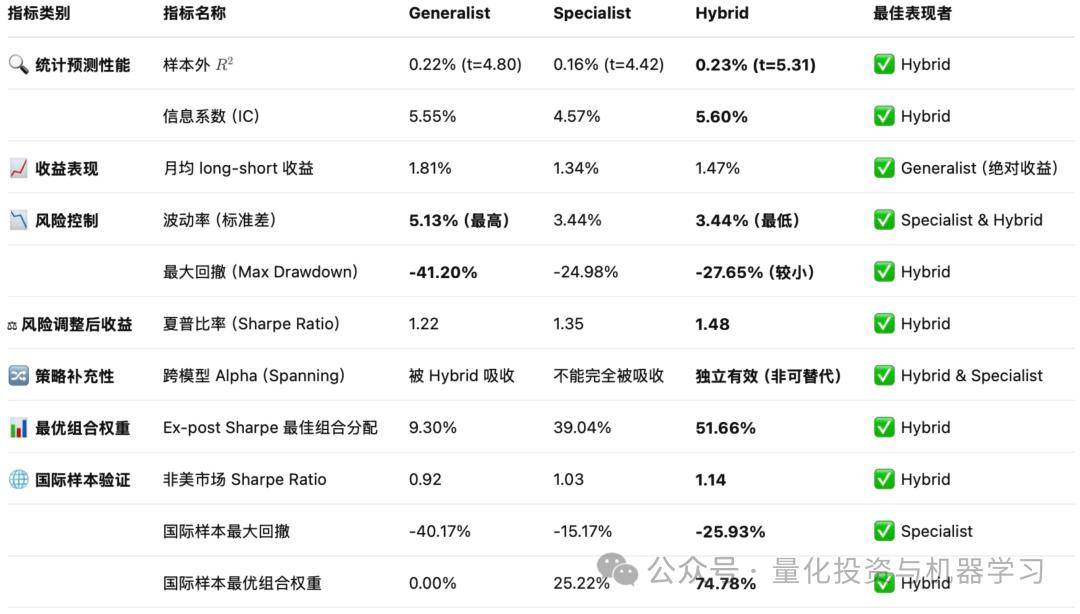
以下是评价指标总结:








评论